That science works merely by testing hypotheses has never been less true than today. As data have become more precise and theories have become more successful, scientists have become increasingly careful in selecting hypotheses before even putting them to test. Commissioning an experiment for every odd idea would be an utter waste of time, not to mention money. But what makes an idea worthy?
Pre-selection of hypotheses is especially important in fields where internal consistency and agreement with existing data are very strong constraints already, and it therefore plays an essential role in the foundation of physics. In this area, most new hypotheses are born dead or die very quickly, and researchers would rather not waste time devising experimental tests for ill-fated non-starters. During their career, physicists must thus constantly decide whether a new ideas justifies spending years of research on it. Next to personal interest, their decision criteria are often based on experience and community norms – past-oriented guidelines that reinforce academic inertia.
Philosopher
Richard Dawid coined the word “post-empirical assessment” for the practice of hypotheses pre-selection, and described it as a non-disclosed Bayesian probability estimate. But philosophy is one thing, doing research another thing. For the practicing scientist, the relevant question is whether a disclosed and organized pre-selection could help advance research. This would require the assessment to be performed in a cleaner way than is presently the case, a way that is less prone to error induced by social and cognitive biases.
One way to achieve this could be to give researchers incentives for avoiding such biases. Monetary incentives are a possibility, but to convince a scientist that their best path of action is putting aside the need to promote their own research would mean incentives totaling research grants for several years – an amount that adverts on nerd pages won’t raise, and thus an idea that seems one of these ill-fated non-starters. But then for most scientists their reputation is more important than money.
 |
Anthony Aquirre.
Image Credits: Kelly Castro. |
And so Anthony Aquirre, Professor of Physics at UC Santa Cruz, devised an algorithm by which scientists can estimate the chances that an idea succeeds, and gain reputation by making accurate predictions. On his website
Metaculus, users are asked to evaluate the likelihood of success for various scientific and technological developments. In the below email exchange, Antony explains his idea.
Bee: Last time I heard from you, you were looking for bubble collisions as evidence of the multiverse. Now you want physicists to help you evaluate the expected impact of high-risk/high-reward research. What happened?
Anthony: Actually, I’ve been thinking about high-risk/high-reward research for longer than bubble collisions!
The Foundational Questions Institute (FQXi) is now in its tenth year, and from the beginning we’ve seen part of FQXi’s mission as helping to support the high-risk/high-reward part of the research funding spectrum, which is not that well-served by the national funding agencies. So it’s a long-standing question how to best evaluate exactly
how high-risk and high-reward a given proposal is.
Bubble collisions are actually a useful example of this. It’s clear that seeing evidence of an eternal-inflation multiverse would be pretty huge news, and of deep scientific interest. But even if eternal inflation is right, there are different versions of it, some of which have bubble and some of which don’t; and even of those that do, only some subset will yield observable bubble collisions. So: how much effort should be put into looking for them? A few years of grad student or postdoc time? In my opinion, yes. A dedicated satellite mission? No way, unless there were some other evidence to go on.
(Another lesson, here, in my opinion, is that if one were to simply accept the dismissive “the multiverse is inherently unobservable” critique, one would never work out that bubble collisions might be observable in the first place.)
B:
What is your relation to FQXi?
A: Max Tegmark and I started FQXi in 2006, and have had a lot of fun (and only a bit of suffering!) trying to build something maximally useful to community of people thinking about the type of foundational, big-picture questions we like to think about.
B:
What problem do you want to address with Metaculus?
Predicting and evaluating (should “prevaluating” be a word?) science research impact was actually — for me — the second motivation for Metaculus. The first grew out of another nonprofit I helped found, the
Future of Life Institute (FLI). A core question there is how major new technologies like AI, genetic engineering, nanotech, etc., are likely to unfold. That’s a hard thing to know, but not impossible to make interesting and useful forecasts for.
FLI and organizations like it could try to build up a forecasting capability by hiring a bunch of researchers to do that. But I wanted to try something different: to generate a platform for soliciting and aggregating predictions that — with enough participation and data generation — could make accurate and well-calibrated predictions about future technology emergence as well as a whole bunch of other things.
As this idea developed, my collaborators (including Greg Laughlin at UCSC) and I realized that it might also be useful in filling a hole in our community’s ability to predict the impact of research. This could in principle help make better decisions about questions ranging from the daily (“Which of these 40 papers in my “to read” folder should I actually carefully read”) to the large-scale (“Should we fund this $2M experiment on quantum cognition?”).
B:
How does Metaculus work?
The basic structure is of a set of (currently) binary questions about the occurrence of future events, ranging from predictions about technologies like
self-driving cars,
Go-playing AIs and
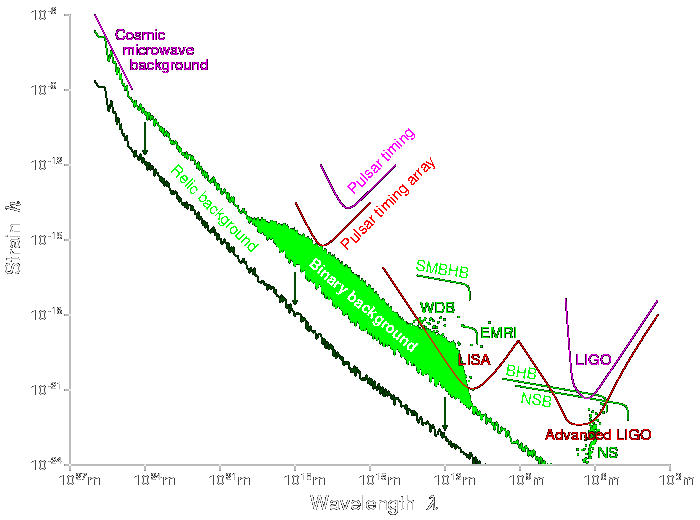
nuclear fusion, to pure science questions such as the detection of
Planet 9, publication of experiments in
quantum cognition or
tabletop quantum gravity, or announcement of the
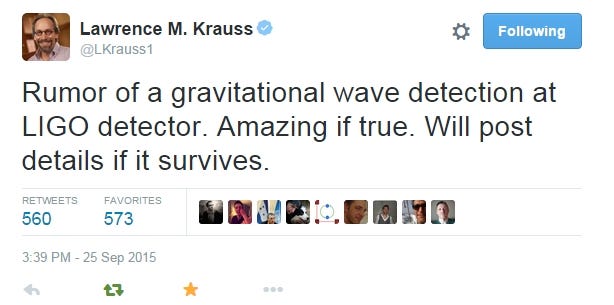
detection of gravitational waves.
Participants are invited assess the likelihood (1%-99%) of those events occurring. When a given question ‘resolves’ as either true or false, points are award depending upon a user's prediction, the community’s predictions, and what actually happened. These points add a competitive game aspect, but serve a more important purpose of providing steady feedback so that predictors can learn how to predict more accurately, and with better calibration. As data accumulations, predictors will also amass a track record, both overall and in particular subjects. This can be used to aggregate predictions into a single, more accurate, one (at the moment, the ‘community’ predictions is just a straight median).
An important aspect of this, I think is not ‘just’ to make better predictions about well-known questions, but to create lots and lots of well-posed questions. It really does make you think about things differently when you have to come up with a well-posed question that has a clear criterion for resolution. And there are lots of questions where even a few predictions (even one!) by the right people can be a very useful resource. So a real utility is for this to be a sort of central clearing-house for predictions.
B:
What is the best possible outcome that you can imagine from this website and what does it take to get there?
A: The best outcome I could imagine would be this becoming really large-scale and useful, like a Wikipedia or Quora for predictions. It would also be a venue in which the credibility to make pronouncements about the future would actually be based on one’s
actual demonstrated ability to make good predictions. There is, sadly, nothing like that in our current public discourse, and we could really use it.
I’d also be happy (if not as happy) to see Metaculus find a more narrow but deep niche, for example in predicting just scientific research/experiment success, or just high-impact technological rollouts (such as AI or Biotech).
In either case, it will take continued steady growth of both the community of users and the website’s capabilities. We already have all sorts of plans for multi-outcome questions, contingent questions, Bayes nets, algorithms for matching questions to predictors, etc. — but that will take time. We also need feedback about what users like, and what they would like the system to be able to do. So please try it out, spread the word, and let us know what you think!












{kind=link}